
Seit der Erstellung dieses Beitrags hat sich diese Website geändert, die Beispiele in diesem Beitrag können nicht mehr exakt wie hier beschrieben nachgestellt werden.
In diesem Artikel werfen wir einen kurzen Blick auf die Entwicklung eines einfachen Webrawlers. Crawler sind kleine automatisierte Scripte die Websites besuchen und gewünschte Informationen daraus extrahieren. Auf Wunsch können Crawler auch mit Websites interagieren, also Formularfelder ausfüllen, Anmeldungen durchführen oder Klicks simulieren. In dieser Anleitung beschränken wir uns auf den Besuch einer Seite und die Auswahl von gewünschten Informationen.
Eines gleich Vorweg, bei der Entwicklung von Crawlern sollte die Idee, so wenig Reibungswärme wie möglich zu erzeugen, immer im Vordergrund stehen. Damit ist gemeint, dass man die jeweils gecrawlte Website nicht mit Anfragen bombadiert sondern zwischen jeder Anfrage etwas Zeit verstreichen lässt. Ziel ist es, dass der Webserver Seiten für andere Nutzern nicht langsamer ausliefert während euer Webrawler seine Arbeit verrichtet. Baut man keine Wartezeiten bzw. Anfragelimits ein, kann ein Crawler schnell in die Sparte der Denial of Service Attacks rutschen. Ein guter Richtwert sind 5 Seiten pro Sekunde je Domain, bei langsamen Webservern oder expliziten Angaben in der robots.txt auch weniger.
Website Auswahl
Für diese Anleitungen nehmen wir uns den Blog von osulzer.at vor. Auf der Übersichtsseite finden wir alle bislang veröffentlichten Einträge. Unser Ziel ist es Titelbilder, Überschriften und Links zu den jeweiligen Beiträgen auszulesen. Da der Blog noch recht neu ist und zum Zeitpunkt dieses Artikels nur insgesamt 4 Beiträge veröffentlicht wurden, werden wir auch die Post-Seiten selbst crawlen um zu zeigen wie man auch zu weiteren Unterseiten springen kann.
Benötigte Tools
Für die Entwicklung unseres Crawlers nutzen wir in dieser Anleitung die folgenden Tools.
- Python 3
- PyCharm – Python Editor mit praktischen Funktionen (kostenlos in der Community Edition)
- Python Packages (können über PyCharm oder pip installiert werden):
- Requests – Schickt Anfragen an Webserver und gibt HTML Code zurück
- BeautifulSoup 4 – Parser der uns dabei hilft Elemente im HTML Code auszuwählen
- cssutils – Parser für CSS Code
- urllib – Hilft uns später im Tutorial dabei, die Domain aus einem Link zu extrahieren
Installiert euch zuerst Python3 und anschließend PyCharm. In den Einstellungen von PyCharm können anschließend „Project Interpreters“ wie Requests oder BeautifulSoup 4 installiert werden. Es empfiehlt sich natürlich ein Virtual Enviorment für das Projekt zu erstellen. Solltet Ihr nichts mit diesem Ausdruck anfangen können und noch recht neu in der Welt von Python sind, könnt Ihr die benötigten Plugins auch einfach auf die normale Art installieren.
Website Analyse
Bevor wir mit der Entwicklung unseres Crawlers starten werfen wir einen Blick auf die zu crawlende Seite. Wir besuchen die Seite im Browser unseres Vertrauens und öffnen die Entwicklerkonsole. Nutzt dafür am besten FireFox oder Chrome.
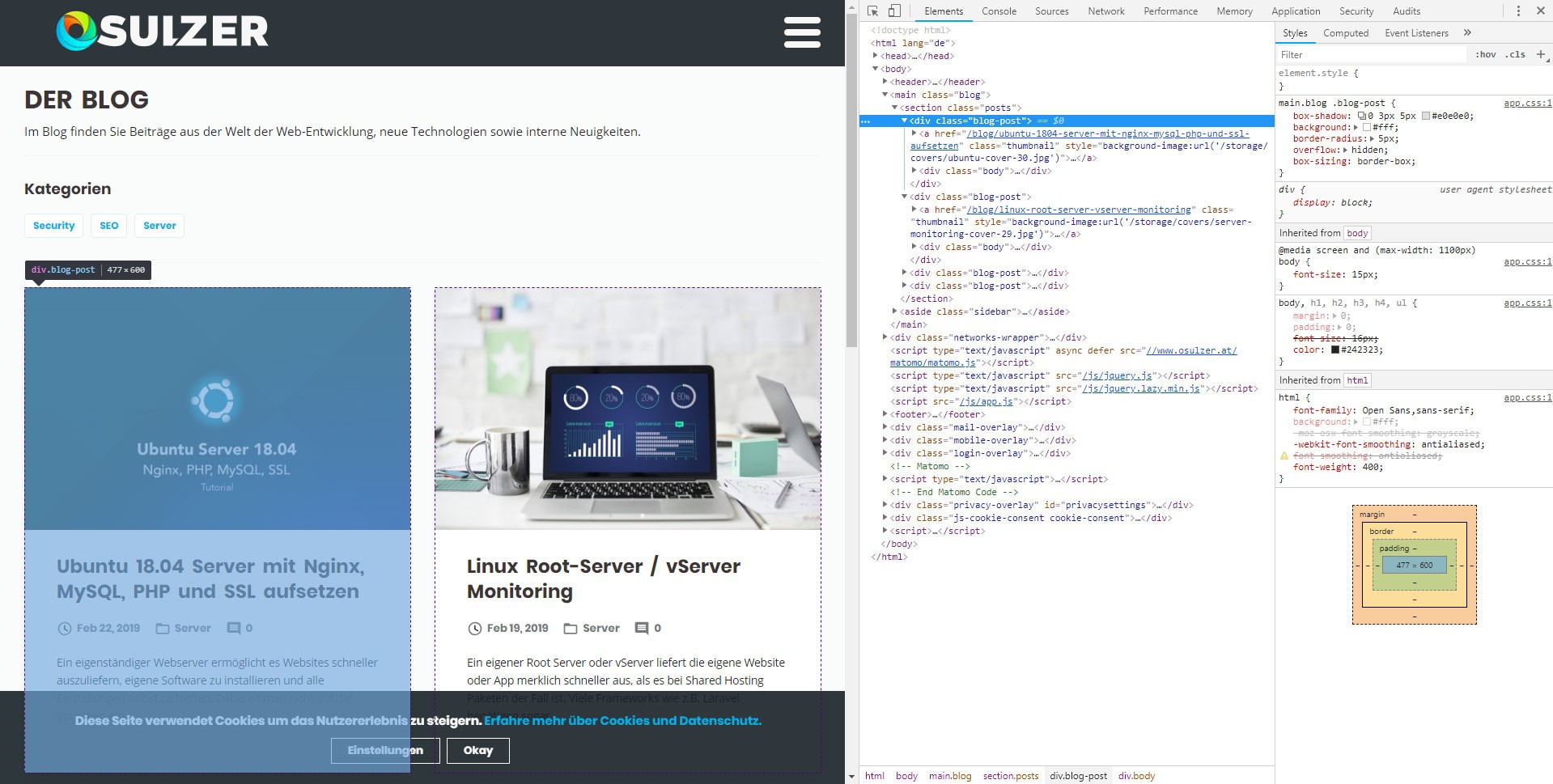
Wir suchen nach Anhaltspunkten um die jeweiligen Elemente der Website voneinander unterscheiden zu können. In unserem Fall finden sich alle Blog Posts unter einer Sektion mit der CSS Klasse „posts“. Jeder Block mit Infos zu dem jeweiligen Eintrag hat anschließend die Klasse „blog-post“. Diese Blöcke beinhalten daraufhin einen Link, den Titel und das Beitragsbild das als Hintergrundbild des Links definiert wurde. Unser Crawler muss also alle HTML Elemente mit der Klasse „blog-post“ finden und die darin enthaltenen Informationen gezielt auslesen.
Der Crawler
HTML Code der Website auslesen
Im ersten Schritt benötigen wir den HTML Code der Blog Startseite. Dazu verwenden wir das zuvor installierte Package „requests“. Requests sendet HTTP Anfragen an die gewünschte URL und gibt anschließend den zurückgegebenen HTML Code aus. In unserem Beispiel packen wir die request-Anfrage in eine eigene Funktion. Das macht es später einfacher auf andere Methoden umzusteigen.
In der Praxis sieht unser Script jetzt wie folgt aus:
import requests
url = 'https://www.osulzer.at/blog'
# gibt html code der gewünschten url zurück
def get_url_content(url):
return requests.get(url).text
Bis jetzt ziemlich einfach. Jetzt importieren wir BeautifulSoup 4 um einfacher mit dem erhaltenen HTML Code arbeiten zu können. Anschließend definieren wir eine neue Funktion in der wir die gewünschte URL Anfragen und den erhaltenen HTML Code an BeautifulSoup 4 übergeben.
def get_blog_content(url):
content = get_url_content(url)
# übergebe html an beautifulsoup parser
soup = BeautifulSoup(content, "html.parser")
„soup“ ist ab sofort ein BeautifulSoup 4 Objekt dessen Inhalt abgefragt werden aknn. Wie weiter oben beschrieben, besitzen alle Blog Posts auf der Blog Startseite die CSS Klasse „blog-post“. Anhand dieser Klasse können wir jetzt den Inhalt den wir benötigen eingrenzen. Dazu nutzen wir BeautifulSoup 4 und suchen alle div Elemente die die gewünschte Klasse haben.
def get_blog_content(url):
content = get_url_content(url)
# übergebe html an beautifulsoup parser
soup = BeautifulSoup(content, "html.parser")
for post in soup.findAll('div', {'class': 'blog-post'}):
print(post.find('h2'))
Dieser Code sollte uns jetzt folgendes ausgeben:
<h2>Ubuntu 18.04 Server mit Nginx, MySQL, PHP und SSL aufsetzen</h2>
<h2>Linux Root-Server / vServer Monitoring</h2>
<h2>WordPress für PageSpeed Insights optimieren</h2>
<h2>Spambot Bekämpfung ohne Captcha Abfrage</h2>
BeautifulSoup 4 gibt uns auch den h2-Tag aus. Um nur an den Text zu kommen müssen wir den Zusatz „.text“ an unsere Abfrage anhängen.
def get_blog_content(url):
content = get_url_content(url)
# übergebe html an beautifulsoup parser
soup = BeautifulSoup(content, "html.parser")
for post in soup.findAll('div', {'class': 'blog-post'}):
print(post.find('h2').text)
Der Output sieht jetzt wie folgt aus:
Ubuntu 18.04 Server mit Nginx, MySQL, PHP und SSL aufsetzen
Linux Root-Server / vServer Monitoring
WordPress für PageSpeed Insights optimieren
Spambot Bekämpfung ohne Captcha Abfrage
Jetzt geht es an das auslesen der anderen Informationen. Den Link zu den jeweiligen Beiträgen bekommen wir indem wir in unserem post Objekt nach dem „a“-Element suchen und daraus anschließend mit .get() den „href“-Tag extrahieren.
Das Hintergrundbild wird per CSS definiert. Damit wir ohne Regex an den verwendeten Link zum Bild kommen nutzen wir das Package „cssutils“. Diesem füttern wir das gefundene Inline CSS per „post.find(‚a‘).get(’style‘)“. Anschließend können wir auf den Wert von „background-image“ zugreifen. Damit wir ausschließlich die Bildadresse erhalten entfernen wir zuvor noch die ungewollten Textstücke am Anfang und Ende.
import requests
from bs4 import BeautifulSoup
import time
import cssutils
url = 'https://www.osulzer.at/blog'
def get_blog_content(url):
content = get_url_content(url)
# übergebe html an beautifulsoup parser
soup = BeautifulSoup(content, "html.parser")
for post in soup.findAll('div', {'class': 'blog-post'}):
# Übergebe inline css an cssutils für einfaches auslesen der attribute
bg = cssutils.parseStyle(post.find('a').get('style'))
print('Title: %s' % post.find('h2').text)
# mithilfe von .get können attribute des "a" elements ausgelesen werden
print('Link: %s' % post.find('a').get('href'))
# der ausgelesene Bild-Link enthält noch ungewollte styling attribute die wir einfach löschen
print('Image: %s' % bg['background-image'].replace('url(', '').replace(')', ''))
Unser neuer Output sieht jetzt wie folgt aus:
Title: Ubuntu 18.04 Server mit Nginx, MySQL, PHP und SSL aufsetzen
Link: /blog/ubuntu-1804-server-mit-nginx-mysql-php-und-ssl-aufsetzen
Image: /storage/covers/ubuntu-cover-30.jpg
Title: Linux Root-Server / vServer Monitoring
Link: /blog/linux-root-server-vserver-monitoring
Image: /storage/covers/server-monitoring-cover-29.jpg
Title: WordPress für PageSpeed Insights optimieren
Link: /blog/wordpress-fur-pagespeed-insights-optimieren
Image: /storage/covers/pagespeed-opener-cover-28.jpg
Title: Spambot Bekämpfung ohne Captcha Abfrage
Link: /blog/spambot-bekampfung-ohne-captcha-abfrage
Image: /storage/covers/mail-spam-cover-25.png
Blog Post Detailseiten crawlen
Unser Crawler kann jetzt die Startseite des Blogs auslesen. Nach dem selben Prinzip können wir auch die gefundenen Unterseiten crawlen. Interessant wäre es zum Beispiel herauszufinden aus wie vielen Wörtern die jeweiligen Posts bestehen. Unsere Vorgehensweise ist wieder die selbe. Zuerst werfen wir einen Blick auf unsere Post-Seite.

In unserem Beispiel wird der Content des Blog Posts in einem div mit der CSS Klasse „textcontent“ dargestellt. Wir nutzen wieder BeautifulSoup 4 um an den Text zu kommen, filtern Sonderzeichen aus dem Text und splitten den String anschließend bei jedem Leerzeichen. Das sieht anschließend folgendermaßen aus. An die (nicht 100% genaue) Wortanzahl kommen wir anschließend mit der len()-Funktion.
def get_blog_post(url):
content = get_url_content(url)
soup = BeautifulSoup(content, "html.parser")
# extrahiere den inhalt aus dem div mit der klasse textcontent
text = soup.find('div', {'class': 'textcontent'}).text
# ersetze sonderzeichen mit leerzeichen
for char in '=+-.,\n':
text = text.replace(char, ' ')
text = text.lower().split()
# gibt die länge des aus split resultierendem list element aus
print('Wörter: %s' % len(text))
Nun müssen wir die neue Funktion nur noch in unserer get_blog_content Funktion einbinden. Bei der Gelegenheit überarbeiten wir auch direkt ein paar Stellen der Funktion damit alles etwas übersichtlicher wird.
def get_blog_content(url):
content = get_url_content(url)
# übergebe html an beautifulsoup parser
soup = BeautifulSoup(content, "html.parser")
for post in soup.findAll('div', {'class': 'blog-post'}):
# Übergebe inline css an cssutils für einfaches auslesen der attribute
bg = cssutils.parseStyle(post.find('a').get('style'))
title = post.find('h2').text
link = post.find('a').get('href')
image = bg['background-image'].replace('url(', '').replace(')', '')
print('Title: %s' % title)
# mithilfe von .get können attribute des "a" elements ausgelesen werden
print('Link: %s' % link)
# der ausgelesene Bild-Link enthält noch ungewollte styling attribute die wir einfach löschen
print('Image: %s' % image)
get_blog_post(link)
Ganz fertig sind wir damit aber noch nicht. Der Link den wir von unserem Blog auslesen ist relativ, wir müssen die komplette URL also zuerst zusammensetzen. Die URL die wir unter der Variable „url“ gespeichert haben, beinhaltet die Domain bereits, wir lesen diese elegant mithilfe des Package urllib aus. Die neue Funktion dafür sieht wie folgt aus:
from urllib.parse import urlparse
def get_domain(url):
parsed_uri = urlparse(url)
return '{uri.scheme}://{uri.netloc}/'.format(uri=parsed_uri)
Die fertig angepasste get_blog_content Funktion sieht anschließend wie folgt aus:
def get_blog_content(url):
content = get_url_content(url)
# übergebe html an beautifulsoup parser
soup = BeautifulSoup(content, "html.parser")
for post in soup.findAll('div', {'class': 'blog-post'}):
# Übergebe inline css an cssutils für einfaches auslesen der attribute
bg = cssutils.parseStyle(post.find('a').get('style'))
title = post.find('h2').text
link = post.find('a').get('href')
image = bg['background-image'].replace('url(', '').replace(')', '')
print('Title: %s' % title)
# mithilfe von .get können attribute des "a" elements ausgelesen werden
print('Link: %s' % link)
# der ausgelesene Bild-Link enthält noch ungewollte styling attribute die wir einfach löschen
print('Image: %s' % image)
get_blog_post(get_domain(url) + link)
Sobald wir den Crawler starten erhalten wir den folgenden Output:
Title: Ubuntu 18.04 Server mit Nginx, MySQL, PHP und SSL aufsetzen
Link: /blog/ubuntu-1804-server-mit-nginx-mysql-php-und-ssl-aufsetzen
Image: /storage/covers/ubuntu-cover-30.jpg
Wörter: 4619
Title: Linux Root-Server / vServer Monitoring
Link: /blog/linux-root-server-vserver-monitoring
Image: /storage/covers/server-monitoring-cover-29.jpg
Wörter: 704
Title: WordPress für PageSpeed Insights optimieren
Link: /blog/wordpress-fur-pagespeed-insights-optimieren
Image: /storage/covers/pagespeed-opener-cover-28.jpg
Wörter: 3779
Title: Spambot Bekämpfung ohne Captcha Abfrage
Link: /blog/spambot-bekampfung-ohne-captcha-abfrage
Image: /storage/covers/mail-spam-cover-25.png
Wörter: 2301
Wenn Ihr den Code selbst ausführt, werdet Ihr merken, dass der Crawler sehr schnell zu Resultaten kommt. In dieser Anleitung arbeiten wir mit requests (eigentlich könnten wir auch ohne weiteres direkt das bereits eingebundene urllib nutzen), Informationen wie Bilder werden nicht übertragen was die Arbeitsgeschwindigkeit nochmals merklich schneller macht als bei Zugriffen mit normalen Browsern. Die schnelle Arbeitsweise des Crawlers kann wie bereits weiter oben angesprochen zu Problemen auf dem Server der zu crawlenden Seite führen. Wir torpedieren den Server über dieses Script mit Anfragen. Um das Script etwas zu entschärfen können Pausen eingebaut werden. Anbieten würde sich dies z.B. in der Funktion „get_url_content()“. Ein einfaches „time.sleep(1)“ verzögert den Ladevorgang jeder übergebenen URL um eine Sekunde. Das Script wird dadurch merklich langsamer, hält sich dafür aber an die Regel den Zielserver nicht unverhältnismäßig zu belasten.
Kurzer Tipp am Rande: Vereinzelt geben Websites in Ihrer robots.txt Datei an wie viel Zeit zwischen Anfragen von Crawlern vergehen muss. Eine Angabe wie z.B. „Crawl-delay: 5“ gibt an, dass zwischen den jeweiligen Anfragen 5 Sekunden vergehen müssen. Respektiert diese Wünsche.
Fertiger Crawler Code
Nachfolgend noch das komplette Script zum selber ausprobieren.
import requests
from bs4 import BeautifulSoup
import time
import cssutils
from urllib.parse import urlparse
url = 'https://www.osulzer.at/blog'
def get_blog_content(url):
content = get_url_content(url)
# übergebe html an beautifulsoup parser
soup = BeautifulSoup(content, "html.parser")
for post in soup.findAll('div', {'class': 'blog-post'}):
# Übergebe inline css an cssutils für einfaches auslesen der attribute
bg = cssutils.parseStyle(post.find('a').get('style'))
title = post.find('h2').text
link = post.find('a').get('href')
image = bg['background-image'].replace('url(', '').replace(')', '')
print('Title: %s' % title)
# mithilfe von .get können attribute des "a" elements ausgelesen werden
print('Link: %s' % link)
# der ausgelesene Bild-Link enthält noch ungewollte styling attribute die wir einfach löschen
print('Image: %s' % image)
get_blog_post(get_domain(url) + link)
def get_blog_post(url):
content = get_url_content(url)
soup = BeautifulSoup(content, "html.parser")
# extrahiere den inhalt aus dem div mit der klasse textcontent
text = soup.find('div', {'class': 'textcontent'}).text
# ersetze sonderzeichen mit leerzeichen
for char in '=+-.,\n':
text = text.replace(char, ' ')
text = text.lower().split()
# gibt die länge des aus split resultierendem list elements aus
print('Wörter: %s' % len(text))
# gibt html code der gewünschten url zurück
def get_url_content(url):
# wartet 1 Sekunde zwischen jeder anfrage
time.sleep(1)
return requests.get(url).text
def get_domain(url):
parsed_uri = urlparse(url)
return '{uri.scheme}://{uri.netloc}/'.format(uri=parsed_uri)
get_blog_content(url)
Fazit
Geschafft, Ihr habt euren ersten Webcrawler entwickelt. Der Crawler ist zwar recht rudimentär, verrichtet seine Arbeit aber trotzdem. Die nächste Ausbaustufe wäre z.B. das Threading der jeweiligen Crawler-Instanzen. Damit können Informationen von gleich mehreren Crawlern heruntergeladen werden. Das wird speziell bei umfangreicheren Websites notwendig um Informationen in einem angemessenen Zeitraumen auslesen zu können. Unser Crawler speichert in seiner jetzigen Form auch noch keine Informationen ab und funktioniert auch nicht auf Seiten die Ihre Inhalte dynamisch laden. Im Fall von dynamischen Websites wie z.B. Facebook müssen wir auf einen sogenannten Headless Browser umsteigen. Dieser erzeugt mehr Overhead, bietet dafür eine verbesserte Kompatibilität.
Sie hätten gerne einen auf Ihre Anforderungen spezialisierten Crawler? Ich biete Webcrawler Entwicklung in Wien und Niederösterreich an. Mehr Informationen zu meinen Leistungen finden Sie unter Crawler und Bot Entwicklung
Abschließend noch ein paar weiterführende Links zu Web Crawlern.
- Scrapy – Ein Webcrawler Framework das viele Funktionen eines Crawlers bereits mit an Board hat.
- Headless Firefox – Infos zum Headless-Modus von Firefox
- Threading – Detailierte Infos zu Python und Threading









