
Vor einigen Wochen erreichte mich eine Nachricht von Philipp Strasser der basierend auf meinem Blog zum Proof of Concept eines Python Grundbuchauszug-Parsers eine erweiterte Version verfasst hat. Die neue Version wurde gegen weitaus mehr Grundbuchauszüge getestet als es bei mir der Fall war und bietet zudem eine GUI über die gleich mehrere Grundbuchauszüge ausgewählt werden können. Die Formatierungen der österreichischen Grundbuchauszüge ist der wilde Westen wodurch Daten teilweise immer noch durch das Suchraster rutschen. Der Output sollte weiterhin kontrolliert und das Script ggf. angepasst werden.
Solltet Ihr das Script selbst erweitern würde ich mich natürlich freuen wenn Ihr euren Code mit mir bzw. dem Internet teilt.
requirements.txt
pandas
openpyxl
tkinter
pdfminer.six
main.py
# © 2022 Oliver Sulzer <office@osulzer.at> https://www.osulzer.at/grundbuchauszug-parser-grundbuchauszuege-auslesen-und-in-excel-csv-oder-andere-formate-exportieren/
# © 2023 Philipp Strasser <philipp.strasser@akzt.gmbh>
import os
import sys
import re
from threading import Thread
import pandas as pd
import tkinter as tk
import tkinter.ttk as ttk
from tkinter import filedialog
from tkinter import messagebox
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.pdfpage import PDFPage
from pdfminer.pdfparser import PDFParser
from io import StringIO
def convert_pdf_to_txt(path):
rsrcmgr = PDFResourceManager()
retstr = StringIO()
codec = 'utf-8'
laparams = LAParams()
device = TextConverter(rsrcmgr, retstr, codec=codec, laparams=laparams)
fp = open(path, 'rb')
interpreter = PDFPageInterpreter(rsrcmgr, device)
password = ""
maxpages = 0
caching = True
pagenos = set()
for page in PDFPage.get_pages(fp, pagenos, maxpages=maxpages, password=password, caching=caching, check_extractable=True):
interpreter.process_page(page)
text = retstr.getvalue()
fp.close()
device.close()
retstr.close()
return text
def cleanup_pdf_text(text):
output = []
for line in text:
if line != '':
output.append(line)
return output
def extract_informations(pdf_file):
pdf_text = iter(cleanup_pdf_text(convert_pdf_to_txt(pdf_file).split('\n')))
output = {}
output['GST'] = []
output['OWNER'] = {}
current_stage = ''
for pdf_line in pdf_text:
if 'Seite' in pdf_line:
continue
if 'KATASTRALGEMEINDE' in pdf_line:
match = re.compile(r'[\s]+\bEINLAGEZAHL\b[\s]+')
output['KG'] = match.split(
pdf_line)[0].strip().lstrip("KATASTRALGEMEINDE").strip()
if 'EINLAGEZAHL' in pdf_line:
match = re.compile(r'\bEINLAGEZAHL\b[\s]+(?P<EZ>\d+)')
output['EZ'] = match.search(pdf_line)['EZ'].strip()
if '**** A1 ****' in pdf_line:
current_stage = 'GST'
if current_stage == 'GST':
match = re.compile(r'^(?P<GST>\d+[/]?[\d]*)[\s]+')
GST = match.match(pdf_line.strip())
if GST:
output['GST'].append(GST['GST'])
if '**** A2 ****' in pdf_line:
current_stage = 'info'
if '**** B ****' in pdf_line:
current_stage = 'owners'
parts_count = 0
if current_stage == 'owners':
if 'ANTEIL:' in pdf_line:
parts_count += 1
output['OWNER'][parts_count] = {}
name = next(pdf_text).strip()
if 'Seite' in name:
name = next(pdf_text).strip()
output['OWNER'][parts_count]["name"] = name
match = re.compile(
r'\bANTEIL\b:\s+(?P<part>\d+)/(?P<parts>\d+)')
parts = match.search(pdf_line)
output['OWNER'][parts_count]["part"] = parts['part']
output['OWNER'][parts_count]["parts"] = parts['parts']
if 'ADR:' in pdf_line:
match = re.compile(
r'\bADR\b:\s+(?P<address>[\w\s\d\.\-/]*),*\s+(?P<plz>\d{4})?')
output['OWNER'][parts_count]['address'] = match.search(pdf_line)[
'address'].strip()
output['OWNER'][parts_count]['plz'] = match.search(pdf_line)[
'plz']
output['OWNER'][parts_count]['city'] = ""
output['OWNER'][parts_count]['geb'] = ""
if ',' in pdf_line:
match = re.compile(
r',\s*(?P<city>[\w\s]*)\s*(?P<plz>\d{4})')
city = match.search(pdf_line)
if city:
output['OWNER'][parts_count]['city'] = city['city'].strip()
plz = match.search(pdf_line)
if plz:
output['OWNER'][parts_count]['plz'] = plz['plz']
if 'GEB:' in pdf_line:
match = re.compile(r'\bGEB\b:\s+(?P<date>\d+-\d+-\d+)')
output['OWNER'][parts_count]['geb'] = match.search(pdf_line)[
'date']
if '**** C ****' in pdf_line:
continue
return output
def create_gb_df(data):
columns = ['GST', 'EZ', 'KG', *data['OWNER'][1].keys()]
df = pd.DataFrame([[data['GST'], data['EZ'], data['KG'], *data['OWNER'][t].values()]
for t in data['OWNER']], columns=columns).explode('GST').set_index('GST')
return df
def export_gb_df_to_file(input_list, output_file):
output_file = os.path.abspath(output_file)
if not os.path.isdir(os.path.dirname(output_file)):
raise Exception("Output Folder not found.")
file_name = os.path.basename(output_file)
file_format = os.path.splitext(file_name)[-1]
files = input_list
df = pd.DataFrame()
for file in files:
print(file)
_i = extract_informations(file)
_df = create_gb_df(_i)
df = pd.concat([df, _df])
match file_format:
case '.xlsx':
sheet_name = os.path.splitext(file_name)[0]
df.to_excel(output_file, sheet_name=sheet_name)
case '.csv':
df.to_csv(output_file, sep=';', encoding='utf-8')
def process_files(input_list, output_file):
export_gb_df_to_file(input_list=input_list, output_file=output_file)
file_name = os.path.basename(output_file)
folder_path = os.path.dirname(output_file)
messagebox.showinfo(
message=f"Der Grundbuchauszug wurde als {file_name} im Ordner {folder_path} gespeichert."
)
pb.stop()
def get_GB_files():
files = filedialog.askopenfilenames(filetypes=[("PDF Datei", "*.pdf")])
set_file_list(list=files, widget=txt_gb_files)
return files
def set_file_list(list, widget):
if list is not None and list:
widget.config(state=tk.NORMAL)
widget.delete("1.0", tk.END)
for file_path in list:
widget.insert(tk.END, file_path + '\n')
widget.config(state=tk.DISABLED)
def save_file():
pb.start()
file_path = filedialog.asksaveasfilename(defaultextension='*.csv',
filetypes=[("Comma Seperated Values", "*.csv"), ("Excel Datei", "*.xlsx")])
gb_files = txt_gb_files.get(1.0, tk.END).strip().split('\n')
thread = Thread(target=process_files, args=(gb_files, file_path))
if file_path is not None and gb_files:
thread.start()
else:
messagebox.showwarning(
message=f"Bitte Grundbuchsauszügen auswählen."
)
pb.stop()
def resource_path(relative_path):
try:
base_path = sys._MEIPASS
except Exception:
base_path = os.path.abspath(".")
return os.path.join(base_path, relative_path)
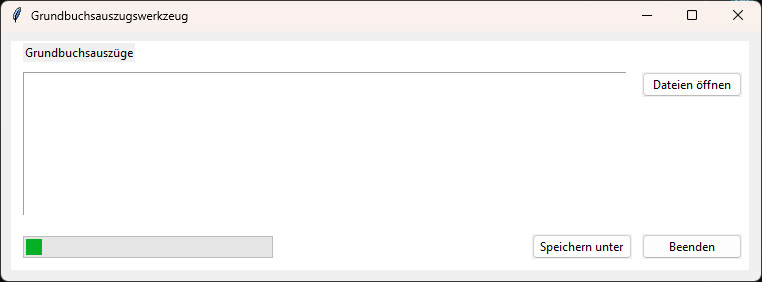
root = tk.Tk()
root.title("Grundbuchsauszugswerkzeug")
root.minsize(750, 250)
root.maxsize(800, 300)
root.geometry("760x250+50+50")
s = ttk.Style()
s.configure('TFrame', background='white')
s.configure('frame.TFrame', background='white')
frame = ttk.Frame(root, width=550, height=100,
borderwidth=2, style='frame.TFrame')
frame.grid(row=0, column=0, padx=10, pady=10)
lbl_gb_folder = ttk.Label(frame,
text="Grundbuchsauszüge")
lbl_gb_folder.grid(row=0, column=0, padx=10, pady=0, sticky="SW")
txt_gb_files = tk.Text(frame,
font=("Arial", 8),
width=100,
height=10,
state=tk.DISABLED
)
txt_gb_files.grid(row=1, column=0, columnspan=2, padx=10, pady=10, sticky="W")
btn_gb_folder = ttk.Button(frame,
width=15,
text="Dateien öffnen",
command=lambda: get_GB_files())
btn_gb_folder.grid(row=1, column=2, padx=5, pady=10, sticky="NE")
pb = ttk.Progressbar(frame,
orient='horizontal',
mode='indeterminate', length=250)
pb.grid(row=2, column=0, columnspan=2, padx=10, pady=10, sticky="W")
btn_save_folder = ttk.Button(frame,
width=15,
text="Speichern unter",
command=lambda: save_file())
btn_save_folder.grid(row=2, column=1, padx=5, pady=5, sticky="E")
btn_cancel = ttk.Button(frame,
width=15,
text="Beenden",
command=lambda: os._exit(0))
btn_cancel.grid(row=2, column=2, padx=5, pady=5, sticky="E")
root.mainloop()









