
Das nachfolgende Code-Snippet entstand aus einem Proof of Concept in dem es darum ging Daten aus österreichischen Grundbuchauszügen auszulesen. Im Detail ging es darum, die Daten der Besitzer inklusive deren Anteile automatisch zu erfassen und anschließend in einer Datenbank zu speichern. Da österreichische Grundbuchauszüge als einfache PDFs ausgegeben werden, besteht die Schwierigkeit darin, die Daten richtig auszulesen. Umgesetzt wurde dies im PoC mit einigen Splits, dem Check ob Sonderzeichen oder Leerzeichen folgen und ein paar anderen Tricks. Einen Schönheitswettbewerb gewinnt der Code nicht, die gewünschten Funktionen konnten aber umgesetzt werden.
Hier findet Ihr die aktualisierte Version des Grundbuchauszugs-Parsers.
Nachfolgend findet Ihr den Python Code.
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from pdfminer.pdfpage import PDFPage
from io import StringIO
from pprint import pprint
def convert_pdf_to_txt(path):
rsrcmgr = PDFResourceManager()
retstr = StringIO()
codec = 'utf-8'
laparams = LAParams()
device = TextConverter(rsrcmgr, retstr, codec=codec, laparams=laparams)
fp = open(path, 'rb')
interpreter = PDFPageInterpreter(rsrcmgr, device)
password = ""
maxpages = 0
caching = True
pagenos = set()
for page in PDFPage.get_pages(fp, pagenos, maxpages=maxpages, password=password,caching=caching, check_extractable=True):
interpreter.process_page(page)
text = retstr.getvalue()
fp.close()
device.close()
retstr.close()
return text
def cleanup_pdf_text(text):
output = []
for line in text:
if line != '':
output.append(line)
return output
pdf_text = cleanup_pdf_text(convert_pdf_to_txt('pdf/GB.pdf').split('\n'))
print(pdf_text)
output = {}
output['anteile'] = {}
temp_output = {}
current_stage = ''
current_substage = ''
current_substage_share = ''
current_substage_part = ''
current_substage_number = ''
for pdf_line in pdf_text:
if 'Seite' in pdf_line:
continue
if '*** B ***' in pdf_line:
current_stage = 'anteile'
if current_stage == 'anteile':
print(pdf_line)
if 'ANTEIL' in pdf_line:
print('------------------------------ Found new Anteil')
current_substage_number = pdf_line.split('ANTEIL:')[0].strip().split(' ')[0].strip()
print(current_substage_number)
current_substage_share = pdf_line.split('ANTEIL:')[1].split('/')[0].strip()
output['total_shares'] = pdf_line.split('ANTEIL:')[1].split('/')[1].strip()
current_substage_part = 'anteilig'
continue
# next line is name of owner
if current_substage_part == 'anteilig':
current_substage_name = pdf_line.strip()
temp_output = {}
temp_output['share'] = current_substage_share
temp_output['name'] = pdf_line.strip()
temp_output['firstname'] = pdf_line.strip().split(' ')[-2]
temp_output['lastname'] = pdf_line.strip().split(' ')[-1]
if len(pdf_line.strip().split(' ')) > 2:
temp_output['title'] = pdf_line.strip().split(' ')[0]
else:
temp_output['title'] = ''
temp_output['family'] = '0'
current_substage_part = 'anteilig-name'
continue
# next line is birthdate and address
if current_substage_part == 'anteilig-name':
print(pdf_line)
address = pdf_line.split('ADR:')[1]
address_with_country = address[:len(address) - 4].strip()
if ',' in address_with_country:
temp_output['address'] = address_with_country.split(',')[0].strip()
temp_output['city'] = address_with_country.split(',')[1].strip()
else:
temp_output['address'] = address_with_country.strip()
temp_output['postal_code'] = address[-4:].strip()
current_substage_part = 'anteil_detail'
continue
if current_substage_part == 'anteil_detail':
if 'Wohnungseigentum an' in pdf_line:
temp_output['apartment'] = pdf_line.split('Wohnungseigentum an')[1].strip()
# we need to find out if the current apartment is already stored in our output array, if not we append
# if found we add a marker called family which indicates that more then one person owns given aparment
add_to_output = True
if len(output['anteile']) > 0:
for index, item in output['anteile'].items():
if item['apartment'] == temp_output['apartment']:
output['anteile'][index]['family'] = 1
if 'family_members' not in output['anteile'][index]:
output['anteile'][index]['family_members'] = []
output['anteile'][index]['family_members'].append(temp_output)
add_to_output = False
if add_to_output is True:
output['anteile'][current_substage_number] = temp_output
current_substage_part = 'finished'
pprint(output)
Der Code speichert die Daten aus dem jeweiligen Grundbuchauszug als Python Array. Die Daten können daraufhin in jedes gewünschte Format ausgegeben werden. Sollten Sie Interesse an der Weiterentwicklung der hier gezeigten Funktionalität haben, können Sie sich gerne bei mir melden.
Nachfolgend findet Ihr einen Demo-Output zur Veranschaulichung der Datenstruktur.
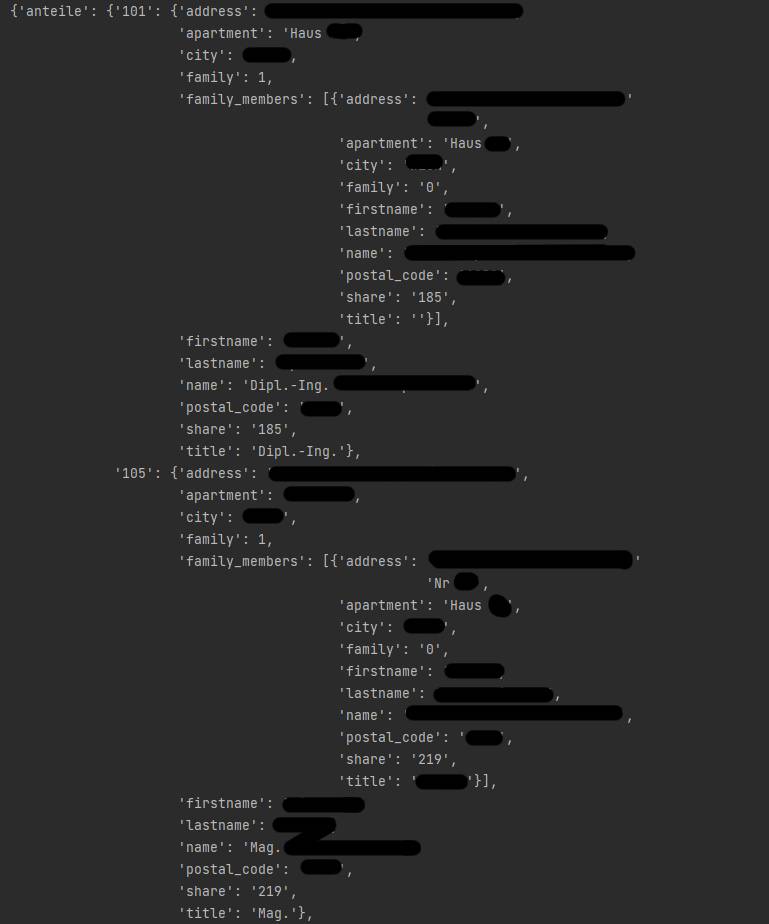
Da es sich um ein Proof of Concept handelt gibt es natürlich noch ein paar scharfe Ecken und Kanten. Soweit ich mich erinnern kann, kommt es bei den Daten derzeit immer wieder vor, dass der Titel von Personen speziell bei Doppelnamen gerne einmal falsch angezeigt wird, an dieser Stelle müsste man also noch nachbessern. Grundlegend sollte aber alles funktionieren. Eure Grundbuch- PDF Datei könnt Ihr bei Zeile 45 angeben. Derzeit geht das Script davon aus, dass der Grundbuchauszug im Ordner „pdf“ liegt und als „GB.pdf“ benannt wurde.
Natürlich kann ich aber keine Garantie dafür geben, dass die ausgelesenen Daten auch fehlerfrei verarbeitet werden, die Benutzung des Codes und der daraus generierten Daten erfolgt also auf eigene Gefahr!









